Darwin Tree of Life: looking back on 2020
Despite restrictions, 2020 has been a busy year for the Darwin Tree of Life Project. We take a look at some of this year’s achievements and highlights.

The Darwin Tree of Life (DToL) Project kicked off in late 2019 with the ambitious task of sequencing, assembling, and annotating the genomes of around 60,000 British and Irish species over a ten-year period.
But when the COVID-19 pandemic hit in early 2020, many of the project’s plans were put on hold. Field work, sampling, and processing of new specimens in the lab were hit most by restrictions put in place to control the spread of the SARS-CoV-2 virus. Despite all this, many significant advances and discoveries were made as part of the DToL project throughout 2020. New species were recorded, DNA extraction methods were refined, and genome annotation became faster than ever before. A parcel of 30 completed genomes was delivered to the public databases at the end of the year.
We take a look back at the work carried out within the DToL project over the last year and shine a light on a few of the biggest highlights of 2020.
Macropis europaea: the Yellow Loosestrife Bee
University of Oxford
This year many species were collected from the Wytham Woods ecological observatory, including new records and rare species. The biggest highlight of the year was the discovery and collection of the Yellow Loosestrife Bee, Macropis europaea. This species was recorded at Wytham for the first time this summer. It is a rare bee in the UK, restricted to mainly wetland sites in southern England. Furthermore, this species is currently the only representative of the Melittidae collected for the project, one of just six families of bees in the UK.

“I was so thrilled to find a population of Macropis thriving at Wytham,” says Liam Crowley, a post-doctoral researcher on the DToL project. “Not only is it the first melittid bee to be sequenced for the project, but it was also a species I had never encountered before despite wanting to see it for long-time!”
M. europaea was also the first monolectic bee species collected for the project. This means it collects pollen from just a single species of flower – yellow loosestrife, Lysimachia vulgaris – which is a relatively unusual trait across UK bee species. Even more exceptionally, it collects floral oils from the yellow loosestrife flowers, to produce an oily wax with which it lines its underground nest cells.
This behaviour is unique amongst British bees, and is believed to assist in waterproofing the cells in order to protect the developing larvae from drowning in the saturated soils of wetland habitats.
The challenges of bryophytes
Royal Botanic Garden Edinburgh
The Royal Botanic Garden Edinburgh grows thousands of species of plants in its four garden sites. While COVID-19 restrictions limited work at wild locations, the Royal Botanic Garden Edinburgh team has benefited from access to the rich Living Collection of species held in care across these four sites.
“There have been opportunities to collect from bryophyte-rich woodland and moorland sites in the Scottish Borders. We have worked closely with the University of Edinburgh, Kew and the British Bryological Society to finalise species lists for the UK and Ireland,” said David Bell, Sample Co-ordinator for the DToL, Royal Botanic Garden Edinburgh.

Bryophytes (mosses, liverworts, and hornworts) bring their own challenges. The combination of their diminutive size and tendency to grow in mixed populations with other bryophytes, fungi, algae and invertebrates, means sampling requires the collection of sufficient relatively clean material.
They must be processed under a microscope to isolate the freshest material of the target species for genome sequencing, with additional samples prepared for DNA barcoding, genome sizing by flow cytometry and voucher herbarium specimens. Sampling sufficient material and targeting larger bryophyte species is particularly important during the early stages of the DToL project while protocols are still being developed.
Sampling sea life: seaweed, sea sponges and sea snails
The Marine Biological Association (MBA)
This year the MBA processed samples for 132 species and set up standard procedures for Macroalgae (seaweed), Porifera (sea sponges), Cnidaria (corals and anemones), Bryozoa (mat animals), Mollusca (sea snails and slugs), Echinodermata (starfish and sea cucumbers), and simple filter feeders such as Tunicata (sea squirts). The first shipment of 568 samples from 53 species was sent to the Wellcome Sanger Institute for genome sequencing in November 2020.

The MBA has also optimised DNA extraction and PCR protocols for many different species of seaweed. To date, they have collected 34 common species. They are also starting to collect protists, very simple eukaryotic organisms that are not considered animals, plants or fungi. Sixteen protist strains are currently being cultivated, while nine have been harvested for DNA extraction.
“Barcoding protocols are currently being developed at MBA by Helen Jenkins and Joanna Harley, and a wider conversation about cross-institutional protocols is occurring with the DToL project collaborators,” says Nova Mieszkowska, MBA Research Fellow. “The methods at MBA aim to firstly confirm identification to species level where possible, and secondly provide ‘deep’ phylogenetic information by methods such as building multigene trees.”
Data collection on the go
The Natural History Museum
In spite of the pandemic, the Natural History Museum (NHM) DToL team have had many highlights this year including the successful development of a sample collection-to-barcode pipeline. The sampling team has completed the arthropod species list and once lockdown was lifted fieldwork trips took place. The team also undertook ad hoc collecting locally when possible. A total of 1034 samples have been collected and are now stored in the NHM Molecular Collection Facility.
The data management team worked hard to get a sample data pipeline in place, setting up the epicollect mobile app for in-field sample data entry. This app helps to ensure that sample data can be exported to the DToL sample tracking system (based on COPO) and stored on the NHM collections management system.
A barcoding pipeline was put in place and collected samples were successfully sequenced, barcodes validated against the BOLD database and the analysed data was then sent over to the Sanger. The NHM team is now fully trained to use their new PacBIO Sequel machine, and they will be validating this system to increase barcoding throughput going forward.
COPO: a big data broker for the DToL
Earlham Institute (EI)
“COPO is something quite special and unique that the science community has long been missing,” says Dr Seanna McTaggart, the Earlham Institute’s (EI) DToL Programme Manager. “For too long, data has been locked away in lab notebooks, or in files on a computer.”
COPO – Collaborative Open Omics – changes that.
COPO is a big data broker for life science. Developed by the Davey Group at EI, COPO takes care of uploading the metadata that are essential for contextualising genomic data. It’s as simple as uploading a spreadsheet, and COPO then does the rest, making sure that data is referred to the correct public repository. In the case of DToL, that is EMBL-EBI’s European Nucleotide Archive (ENA).

“COPO ensures that metadata is validated,” said EI Research Software Engineer Alice Minotto in a recent interview. “This could be metadata such as taxonomy, which can be tricky as identifying organisms is not a fixed process. Names and species identification can change over time, and even within specific communities.
“Instead of having to check and submit this information manually, which would take a very long time, COPO automates the process. This makes it far less time-consuming, easier, and eliminates errors.”
To find out more about COPO, contact Dr Felix Shaw and Alice Minotto via the COPO website.
Large-scale sampling and tricky, slimy species
Wellcome Sanger Institute
It has been a tumultuous year for Sanger’s DToL team as they started to set up large-scale DNA sampling and sequencing pipelines from scratch, only for coronavirus to shut down scientific operations for several months. Caroline Howard, Scientific Manager for Sanger’s Tree of Life Programme, says the team have done an outstanding job.
“I think one of our biggest achievements has to be that we’re now properly up and running, despite the disruption of coronavirus. The support from our colleagues in sequencing operations has been amazing, particularly Elizabeth Cook, Craig Corton, Karen Oliver and Mike Quail.”

Sanger now has a fully-functioning tracking system where samples from the same specimen are submitted for the various sequencing techniques required, at a rate of 20-30 species per week. People may think extracting and sequencing DNA is the same for all families and species, but in fact different taxa pose different challenges that have to be solved each time.
“We’ve had a lot of success processing butterfly and moth samples this year, but slimy species such as molluscs continue to be tricky. But we’ve come a long way. A great example of how far our pipelines have come is Patella pellucida, the blue-rayed limpet. This sample was collected by Sanger faculty at Millport, Scotland at the end of August. Within five weeks, it had been received in the lab, gone through sample management, validated using COPO, put through our protocols for DNA extraction and sub-sampling, and submitted for sequencing.”
“We’re now assembling all of the data to reference genome standard. I think this represents an impressive turnaround time from collection to reference genome, and stands us in good stead to scale up in the year ahead.”
At the end of the year, the Sanger teams celebrated the formal release of the first 30 DToL species’ genome sequences to the European Nucleotide Archive. These assemblies are of uniformly high quality, with all the sequences assigned to chromosomes. Hundreds more are now in the sequencing, assembly and curation pipeline.
Illuminating nature’s dark matter: protists and single cell genomics
EI and University of Oxford
Protists make up the overwhelming majority of eukaryotic life but until now have remained relatively understudied. Researchers in the Hall group at EI and the Tom Richards lab at the University of Oxford are changing that, aiming to sample and decode the breadth of protist diversity across the British Isles.
That’s no easy task. ‘Protist’ is a word that describes a staggering range of lifeforms, some with genomes as small as a bacterium while others boast far greater complexity than that of the human genome. At EI, Dr Sally Warring has been working with the Single Cell Genomics team to coax the genetic information from this mysterious myriad of lifeforms.
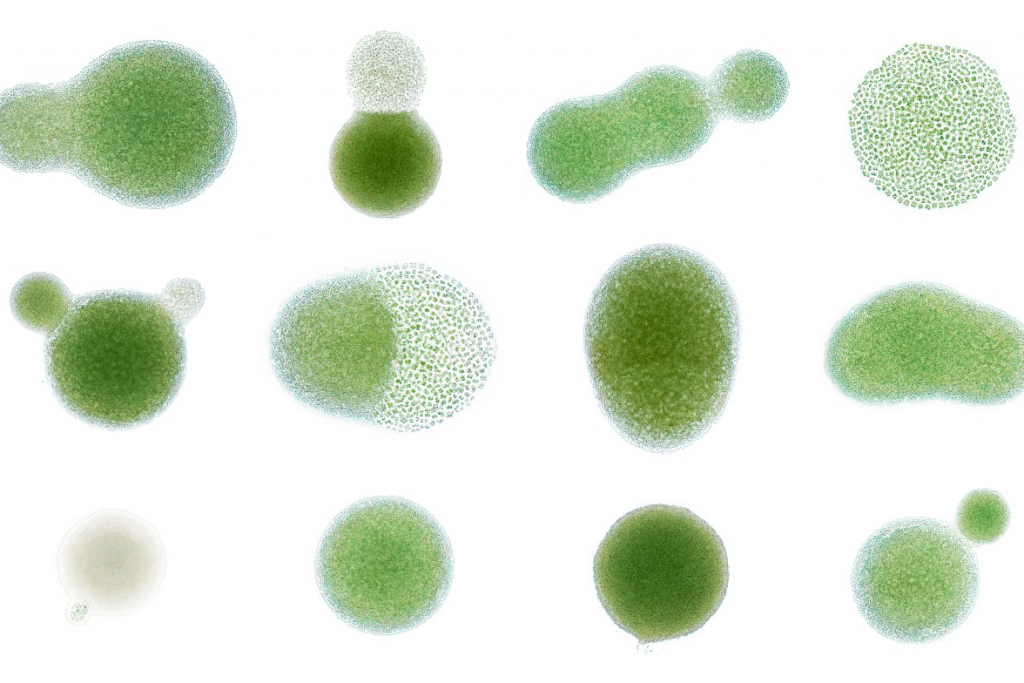
“Protists are so variable,” Warring explained to us in a recent interview. “Some have thick cell walls, some have glass cell walls, some have silica scales on them, some have starch – all these different things going on with their cell chemistry. This all makes DNA extraction, or the ability of an enzyme to work, highly variable.
“What I’m doing now is culturing protists to use Hi-C [a chromosome capturing mechanism], which looks at the proximity of DNA sequences to each other to get a better idea about the structure of genomic sequences. We’re trying to establish this in our single cell pipeline, possibly from metagenomic samples, to get better single cell genomes.”
Rapid access to the DToL genomes
EMBL’s European Bioinformatics Institute (EMBL-EBI)
One important goal of the DToL project is to make all of the newly sequenced genomes fully accessible to all researchers. Every genome sequence from the DToL project will be freely available through EMBL’s European Bioinformatics Institute’s (EMBL-EBI) database, the European Nucleotide Archive (ENA). Each of the genome sequences collected will also be annotated, stored and made available through the Ensembl genome browser. Both the ENA and Ensembl have made significant changes to their underlying processes to be as efficient as possible and keep up with the enormous scale of the DToL project.
These changes, driven by a need for rapid access to genome annotations at scale, led to the launch of Ensembl Rapid Release. Rapid Release is a lightweight, scalable version of the Ensembl genome browser designed to house annotations for species from DToL and other sequencing efforts.
Unlike the main Ensembl website, which updates every three months, Rapid Release is updated every two weeks with new species and annotations. As a result, downstream research can begin within weeks of the annotation being finalised – a huge benefit to the DToL project as the number of genomes begins to ramp up.
“Five months after the launch of Ensembl Rapid Release, we already have over 170 genomes from DToL and other projects,” says Fergal Martin, Vertebrate Annotation Coordinator at EMBL-EBI. “As we get more genomic and transcriptomic data from DToL we can now roll out the annotations on Rapid Release.”
These are just some of the amazing achievements made by the DToL project this year and this is just the beginning. Thousands of new genomes will be sequenced in the coming years as the DToL project gears up to sequence entire ecosystems.
As the DToL project expands to collect and sequence more species, researchers can expect to see more new genomes released and made freely accessible. In the near future, the DToL project will also provide a great opportunity to bring people closer to nature and give us a better understanding of how we can protect our planet.
This post was originally published on EMBL-EBI News.
The Darwin Tree of Life Project
The Darwin Tree of Life Project is an ambitious programme to sequence, assemble and openly publish the genomes of over 60,000 species of animals, plants, fungi and protists in Britain and Ireland. The Project contributes to the global mission to sequence all life, the Earth Biogenome Project. The genomic data generated will revolutionise bioscience forever, facilitating research into evolution and biology, conservation of biodiversity, and the development of new biomaterials and pharmaceuticals.
The Darwin Tree of Life Project is being undertaken by a consortium of ten Partners: the Earlham Institute, EMBL’s European Bioinformatics Institute (EMBL-EBI), Marine Biological Association, Natural History Museum, Royal Botanical Garden Edinburgh, Royal Botanical Gardens Kew, University of Cambridge, University of Oxford, University of Edinburgh and the Wellcome Sanger Institute.