English
English Čeština
Čeština Ελληνικά
Ελληνικά Italiano
Italiano Svenska
Svenska
Chasse au trésor GFP – Introduction
Introduction
À quoi ressemble une séquence biologique et quelles sont les utilisations que pouvez-vous en faire ?
Imaginez un instant que le centre du génome EMBL possède des séquences d’échantillons d’ADN de différentes protéines fluorescentes. Avant de commencer vos analyses bioinformatiques de ces échantillons, lisez les informations ci-dessous afin de voir à quoi ressemble les résultats du séquençage de l’ADN.
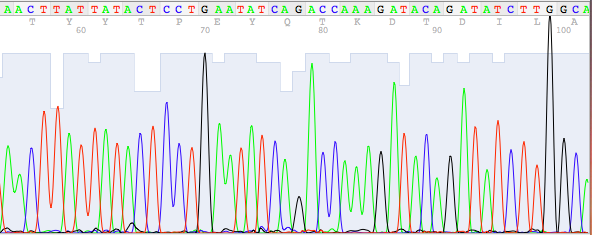
Les résultats du séquençage de l’ADN peuvent être visualisés de deux manières différentes :
1. Chromatogramme d’une séquence
Un chromatogramme de séquence permet d’afficher les données produites sous forme de “pics” par l’appareil de séquençage.
Une couleur différente est déterminée pour chacune des 4 bases :
A = vert , C = bleu , G = noir, T = rouge
A = vert , C = bleu , G = noir, T = rouge
La séquence d’ADN peut ainsi être “lue” comme une séquence de pics individuels. L’exemple suivant représente le chromatogramme d’une telle séquence :
2. Fichiers texte en format FASTA
Le format FASTA est un format texte qui permet d’afficher et de stocker des séquences d’acides nucléïques (ADN et ARN) et d’acides aminés (protéines). Chaque séquence débute par le symbole “plus grand que” (>) et par une en-tête descriptive (le nom de la séquence) Le nom de la séquence est ajouté à la suite sans espace. Les lignes qui suivent contiennent les données de la séquence. Les exemples suivants illustrent une séquence représentée en format FASTA :
>Human_1233_P1 AGGAGCAGGGAGGGCAGGAGCCAGGGCTGGGCATAAAAGTCAGGGCAGAGCCATCTATTGCTTACATTTGCTTCTGACACAACTGTGTTCACTAGCAACCTCAAACAGACACCATGGTGCACCTGACTCCTGAGGAGAAGTCTGCCGTTACTGCCCTGTGGGGCAAGGTGAACGTGGATGGAAGTTGGTGGTGAGGCCCTGGGCAGGTTGGTATCAAGGTTACAAGACAGGTTTAAGGAGACCAATAGAAACTGGGCATGTGGAGACAGAGAAGACTCTTGGGTTTCTGATAGGCACTGACTCTCTCTGCCTATTGGTCTATTTTCCCACCCTTAGGCTGCTGGTGGTCTACCCTTGGACCCAGAGGTTCTTTGAGTCCTTTGGGGATCTGTCCACTCCTGATGCTGTTATGGGCAACCCTAAGGTGAAGGCTCATGGCAAGAAAGTGCTCGGTGCCTTTAGTGATGGCCTGGCTCACCTGGACAACCTCAAGGGCACCTTTGCCACACTGAGTGAGCTGCACTGTGACAAGCTGCACGTGGATCCTGAGAACTTCAGGGT
Dans les séquences en format FASTA, des codes à 1 lettre sont utilisés pour représenter les acides nucléiques et les acides aminés:
Codes à 1 lettre pour les acides nucléiques :
Adenine = A
Cytosine = C
Guanine = G
Thymine = T
Codes à 1 lettre pour les acides aminés :
Alanine A, Arginine R, Asparagine N, Aspartate D, Cysteine C, Glutamine Q, Glutamic acid E, Glycine G, Histidine H, Isoleucine I, Leucine L, Lysine K, Methionine M, Phenylalanine F, Proline P, Serine S, Threonine T, Tryptophane W, Tyrosine Y, Valine V
Navigation d’activité
Share: