English
English Čeština
Čeština Ελληνικά
Ελληνικά Italiano
Italiano Svenska
Svenska
Étape 3 : Traduction de l’ARN messager
Aperçu
Dans cette partie de l’activité, nous traduirons des séquences d’ARN messager des quatre protéines flurosecentes en séquences d’acides aminés. Pour y arriver, nous utiliserons un outil appelé le EMBOSS Transeq (European Molecular Biology Open Software Suite Transeq). Cet outil web simule la traduction des séquences d’ARN messager en séquence d’acides aminés dans le code à une lettre.
Tâche
Suivez la procédure suivante :
- Allez à l’onglet “Séquence 1” et copiez la séquence complète de l’ARN messager qui débute par >Séquence1 (vous pouvez utiliser le raccourci clavier Ctrl +C).
- Collez la séquence de nucléotides dans la zone de recherche EMBOSS Transeq (vous pouvez utiliser le raccourci clavier Ctrl + V).
- Suivez les instructions sous l’onglet “EMBOSS Transeq” pour traduire votre séquence.
- Observez votre protéine et essayez de répondre aux questions sous l’onglet “Questions”.
- Répétez la même procédure pour les 4 séquences.
EMBOSS Transeq
- Allez à l’onglet “Séquence 1” et copiez la séquence complète de l’ARN messager qui débute avec >Séquence1 (vous pouvez utiliser le raccourci clavier Ctrl +C).
- Collez la séquence de nucléotides dans la zone de recherche EMBOSS Transeq (utilisez le raccourci clavier Ctrl + V).
- Conservez tous les autres paramètres.
- Cliquez simplement sur le gros bouton “Envoyer” et votre séquence sera traduite.
- Vous pourrez voir le résultat en quelques secondes.
- Observez votre protéine et essayez de répondre aux questions sous l’onglet “Questions”.
- Répétez la même procédure pour les 4 séquences.
Séquences 1-4
Séquence 1
>Sequence1_AVGFP
ATGAGTAAAGGAGAAGAACTTTTCACTGGAGTGGTCCCAGTTCTTGTTGAATTAGATGGCGATGTTAATGGGCAAAAATTCTCTGTCAGTGGAGAGGGTGAAGGTGATGCAACATACGGAAAACTTACCCTTAATTTTATTTGCACTACTGGGAAGCTACCTGTTCCATGGCCAACACTTGTCACTACTTTCTCTTATGGTGTTCAATGCTTCTCAAGATACCCAGATCATATGAAACAGCATGACTTTTTCAAGAGTGCCATGCCCGAAGGTTATGTACAGGAAAGAACTATATTTTACAAAGATGACGGGAACTACAAGACACGTGCTGAAGTCAAGTTTGAAGGTGATACCCTTGTTAATAGAATCGAGTTAAAAGGTATTGATTTTAAAGAAGATGGAAACATTCTTGGACACAAAATGGAATACAACTATAACTCACATAATGTATACATCATGGGAGACAAACCAAAGAATGGCATCAAAGTTAACTTCAAAATTAGACACAACATTAAAGATGGAAGCGTTCAATTAGCAGACCATTATCAACAAAATACTCCAATTGGCGATGGCCCTGTCCTTTTACCAGACAACCATTACCTGTCCACACAATCTGCCCTTTCCAAAGATCCCAACGAAAAGAGAGATCACATGATCCTTCTTGAGTTTGTAACAGCTGCTAGGATTACACATGGCATGGATGAACTATACAAA
Séquence2
>Sequence2_GFPm
ATGTCTAAAGGTGAAGAATTATTCACTGGTGTTGTCCCAATTTTGGTTGAATTAGATGGTGATGTTAATGGTCACAAATTTTCTGTCTCCGGTGAAGGTGAAGGTGATGCTACTTACGGTAAATTGACCTTAAAATTTATTTGTACTACTGGTAAATTGCCAGTTCCATGGCCAACCTTAGTCACTACTTTCGGTTATGGTGTTCAATGTTTTGCTAGATACCCAGATCATATGAAACAACATGACTTTTTCAAGTCTGCCATGCCAGAAGGTTATGTTCAAGAAAGAACTATTTTTTTCAAAGATGACGGTAACTACAAGACCAGAGCTGAAGTCAAGTTTGAAGGTGATACCTTAGTTAATAGAATCGAATTAAAAGGTATTGATTTTAAAGAAGATGGTAACATTTTAGGTCACAAATTGGAATACAACTATAACTCTCACAATGTTTACATCATGGCTGACAAACAAAAGAATGGTATCAAAGTTAACTTCAAAATTAGACACAACATTGAAGATGGTTCTGTTCAATTAGCTGACCATTATCAACAAAATACTCCAATTGGTGATGGTCCAGTCTTGTTACCAGACAACCATTACTTATCCACTCAATCTGCCTTATCCAAAGATCCAAACGAAAAGAGAGACCACATGGTCTTGTTAGAATTTGTTACTGCTGCTGGTATTACCCATGGTATGGATGAATTGTACAAATAACTGCAG
Séquence 3
>Sequence3_YFP
AATATTTTTATTAATTCATTAGAAAAATGAGAGGAAGGATTATTATGTTTAAAGGTATAGTAGAAGGTATAGGAATCATTGAAAAAATTGATATATATACTGACCTAGATAAGTATGCAATTCGATTTCCTGAAAATATGTTGAATGGAATTAAAAAGGAGTCGTCAATAATGTTTAACGGATGCTTCTTAACGGTAACTAGCGTGAATTCAAACATTGTCTGGTTTGATATATTTGAAAAAGAAGCACGTAAGCTTGATACTTTTCGGGAATATAAGGTAGGTGACCGAGTAAATTTAGGAACATTCCCAAAATTTGGCGCTGCATCTGGTGGGCATATATTATCAGCAAGGATTTCATGTGTAGCAAGTATTATTGAAATAATAGAAAATGAGGATTATCAACAAATGTGGATTCAAATTCCTGAAAATTTTACAGAGTTTCTTATTGATAAAGACTATATTGCTGTGGATGGTATTAGCTTAACTATTGACACTATAAAAAACAACCAATTTTTCATTAGTTTACCCTTAAAAATAGCACAAAATACAAATATGAAATGGCGAAAAAAAGGTGATAAGGTAAATGTTGAGTTATCAAACAAAATTAATGCTAACCAGTGTTGGTAATTTACTGAGGATAGTAAAAATGAACTGTTTAAAATAATATTTAAATTTTTATTTATAATACAGAGTCAGTTGTTGTAAATAGTCTGAGTGGTAAATAAGTTCTACCATTAATTAAATATTATCCATATTAAATAAAGGATCT
Séquence 4
>Sequence4_RFP
AGTTTCAGCCAGTGACAGGGTGAGCTGCCAGGTATTCTAACAAGATGAGTTGTTCCAAGAATGTGATCAAGGAGTTCATGAGGTTCAAGGTTCGTATGGAAGGAACGGTCAATGGGCACGAGTTTGAAATAAAAGGCGAAGGTGAAGGGAGGCCTTACGAAGGTCACTGTTCCGTAAAGCTTATGGTAACCAAGGGTGGACCTTTGCCATTTGCTTTTGATATTTTGTCACCACAATTTCAGTATGGAAGCAAGGTATATGTCAAACACCCTGCCGACATACCAGACTATAAAAAGCTGTCATTTCCTGAGGGATTTAAATGGGAAAGGGTCATGAACTTTGAAGACGGTGGCGTGGTTACTGTATCCCAAGATTCCAGTTTGAAAGACGGCTGTTTCATCTACGAGGTCAAGTTCATTGGGGTGAACTTTCCTTCTGATGGACCTGTTATGCAGAGGAGGACACGGGGCTGGGAAGCCAGCTCTGAGCGTTTGTATCCTCGTGATGGGGTGCTGAAAGGAGACATCCATATGGCTCTGAGGCTGGAAGGAGGCGGCCATTACCTCGTTGAATTCAAAAGTATTTACATGGTAAAGAAGCCTTCAGTGCAGTTGCCAGGCTACTATTATGTTGACTCCAAACTGGATATGACGAGCCACAACGAAGATTACACAGTCGTTGAGCAGTATGAAAAAACCCAGGGACGCCACCATCCGTTCATTAAGCCTCTGCAGTGAACTCGGCTCAGTCATGGATTAGCGGTAATGGCCACAAAAGGCACGATGATCGTTTTTTAGGAATGCAGCCAAAAATTGAAGGTTATGACAGTAGAAATACAAGCAACAGGCTTTGCTTATTAAACATGTAATTGAAAAC
Diagramme des codons
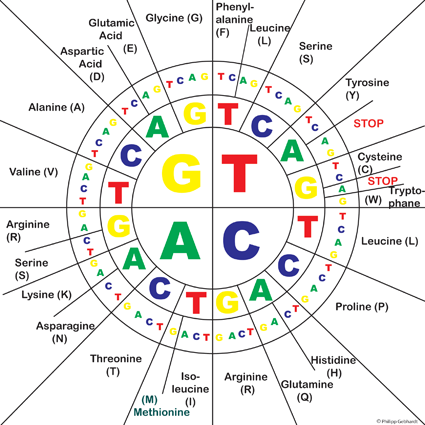
Questions
- Comment une séquence d’ADN est-elle traduite en séquence d’acides aminés ? Décrivez, d’une manière simple, chacune des étapes de ce processus. Si vous le voulez, utilisez le Diagramme circulaire des codons sous l’onglet correspondant.
- Pourvez vous trouver le “bon” cadre de lecture ouvert ?
- D’après vous, dans le résultat EMBOSS Transeq, que signifie l’astérisque ( *) ?
Navigation d’activité
Share: