English
English Čeština
Čeština Français
Français Ελληνικά
Ελληνικά Svenska
Svenska
Caccia al tesoro GFP – Introduzione
Introduzione
Come appare una sequenza biologica e cosa ci possiamo fare?
Immaginate che la the EMBL Genomics Core Facility abbia sequenziato campioni di DNA di differenti proteine fluorescenti. Prima di iniziare la vostra analisi bioinformatica su questi campioni, leggete qui sotto per capire che aspetto hanno i risultati del sequenziamento del DNA.
I risultati del sequenziamento del DNA possono essere visualizzati in due modi :
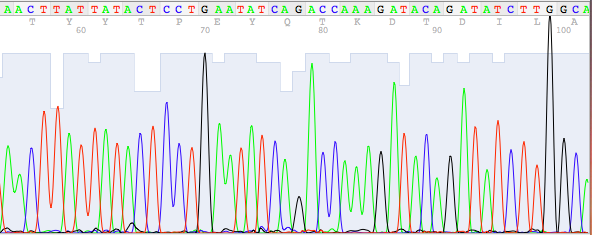
1. Cromatogrammi di sequenziamento
Un cromatogramma di sequenziamento mostra i dati prodotti dalla macchina sequenziatrice sotto forma dei cosiddetti “picchi”.
A ciascuna delle 4 basi azotate è assegnato un diverso colore :
A = verde , C = blu , G = nero, T = rosso
A = verde , C = blu , G = nero, T = rosso
la sequenza del DNA può essere “letta” come sequenza dei singoli picchi. L’esempio seguente illustra uno di questi cromatogrammi di sequenziamento:
2. File di testo in formato FASTA
Il formato FASTA è un formato di testo utilizzato per mostrare e archiviare sequenze di acidi nucleici (DNA e RNA) e di aminoacidi (proteine).
Ogni sequenza inizia con una riga contenente il segno maggiore (>) ed un’intestazione descrittiva (che è il nome della sequenza). Il nome della sequenza é aggiunto dopo il segno > senza spazio. Le righe seguenti contengono la sequenza. Qui sotto è riportato un esempio di una sequenza in formato FASTA :
>Human_1233_P1 AGGAGCAGGGAGGGCAGGAGCCAGGGCTGGGCATAAAAGTCAGGGCAGAGCCATCTATTGCTTACATTTGCTTCTGACACAACTGTGTTCACTAGCAACCTCAAACAGACACCATGGTGCACCTGACTCCTGAGGAGAAGTCTGCCGTTACTGCCCTGTGGGGCAAGGTGAACGTGGATGGAAGTTGGTGGTGAGGCCCTGGGCAGGTTGGTATCAAGGTTACAAGACAGGTTTAAGGAGACCAATAGAAACTGGGCATGTGGAGACAGAGAAGACTCTTGGGTTTCTGATAGGCACTGACTCTCTCTGCCTATTGGTCTATTTTCCCACCCTTAGGCTGCTGGTGGTCTACCCTTGGACCCAGAGGTTCTTTGAGTCCTTTGGGGATCTGTCCACTCCTGATGCTGTTATGGGCAACCCTAAGGTGAAGGCTCATGGCAAGAAAGTGCTCGGTGCCTTTAGTGATGGCCTGGCTCACCTGGACAACCTCAAGGGCACCTTTGCCACACTGAGTGAGCTGCACTGTGACAAGCTGCACGTGGATCCTGAGAACTTCAGGGT
Nelle sequenza in formato FASTA codici di 1 lettera sono utilizzati per gli acidi nucleici e per gli aminoacidi:
Codici di 1 lettera per gli acidi nucleici:
Adenina = A
Citosina = C
Guanina = G
Timina = T
codici di 1 lettera per gli aminoacidi:
Alanina A, Arginina R, Asparagina N, Aspartato D, Cisteina C, Glutamina Q, Acido glutamico E, Glicina G, Istidina H, Isoleucina I, Leucina L, Lisina K, Metionina M, Fenilalanina F, Prolina P, Serina S, Treonina T, Triptofano W, Tirosina Y, Valina V
Navigazione attività
Share: