 English
English Français
Français Ελληνικά
Ελληνικά Italiano
Italiano Svenska
Svenska
Honba za pokladem – GFP – úvod
Úvod
Jak vypadá biologická sekvence a co všechno se s ní dá dělat?
Představte si, že vaše sekvenační centrum osekvenovalo DNA vzorky několika fluorescenčních proteinů. Předtím, než začnete analyzovat sekvenační výsledky, podívejte se jak vlastně takové výsledky vypadají.
Výsledky sekvenace DNA se dají zobrazit dvěma hlavními způsoby:
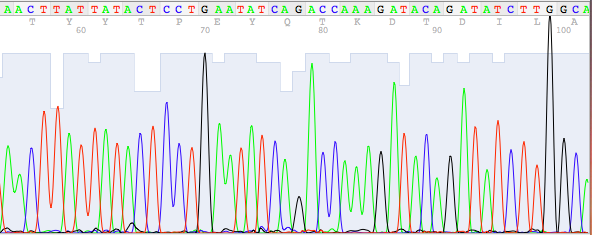
1. Sekvenační chromatogramy
Sekvenační chromatogram ukazuje přímo výstup ze sekvenačního přístroje v podobě vrcholů (tzv. “peaků”).
Každá báze má jinou barvu:
A = zelená
, C = modrá,G = černá, T = červená
DNA sekvence se tak dá číst jako sekvence jednotlivých “peaků”. Zde je příklad takového sekvenačního chromatogramu:
2. Textové soubory ve formátu FASTA
FASTA formát je obecný textový formát k ukládání a zobrazování nukleotidových (DNA a RNA) i proteinových sekvencí. Tento formát vždy obsahuje řádek se znaménkem “větší než” – “>”, následovaným názvem či krátkým popisem sekvence. Název sekvence následuje za znaménkem “>” bez jakékoliv mezery. Další řádek obsahuje samotnou sekvenci. Zde je příklad nukleotidové sekvence ve formátu FASTA:
>Human_1233_P1 AGGAGCAGGGAGGGCAGGAGCCAGGGCTGGGCATAAAAGTCAGGGCAGAGCCATCTATTGCTTACATTTGCTTCTGACACAACTGTGTTCACTAGCAACCTCAAACAGACACCATGGTGCACCTGACTCCTGAGGAGAAGTCTGCCGTTACTGCCCTGTGGGGCAAGGTGAACGTGGATGGAAGTTGGTGGTGAGGCCCTGGGCAGGTTGGTATCAAGGTTACAAGACAGGTTTAAGGAGACCAATAGAAACTGGGCATGTGGAGACAGAGAAGACTCTTGGGTTTCTGATAGGCACTGACTCTCTCTGCCTATTGGTCTATTTTCCCACCCTTAGGCTGCTGGTGGTCTACCCTTGGACCCAGAGGTTCTTTGAGTCCTTTGGGGATCTGTCCACTCCTGATGCTGTTATGGGCAACCCTAAGGTGAAGGCTCATGGCAAGAAAGTGCTCGGTGCCTTTAGTGATGGCCTGGCTCACCTGGACAACCTCAAGGGCACCTTTGCCACACTGAGTGAGCTGCACTGTGACAAGCTGCACGTGGATCCTGAGAACTTCAGGGT
Pro sekvence ve formátu FASTA se pro jednotlivé báze či aminokyseliny používají jednopísmenné kódy:
1-písmenné kódy pro nukleové kyseliny:
Adenine = A
Cytosine = C
Guanine = G
Thymine = T
1-písmenné kódy pro aminokyseliny:
Alanine A, Arginine R, Asparagine N, Aspartate D, Cysteine C, Glutamine Q, Glutamic acid E, Glycine G, Histidine H, Isoleucine I, Leucine L, Lysine K, Methionine M, Phenylalanine F, Proline P, Serine S, Threonine T, Tryptophane W, Tyrosine Y, Valine V
Navigace aktivity
Share:


