English
English Čeština
Čeština Français
Français Ελληνικά
Ελληνικά Svenska
Svenska
Step 3: Traduzione degli mRNA
Descrizione
In questa parte dell’attività, le sequenze degli mRNA delle quattro proteine fluorescenti verranno tradotte nelle sequenze di aminoacidi. Per fare questo, verrà utilizzato uno strumento chiamato EMBOSS Transeq (European Molecular Biology Open Software Suite Transeq). Questo strumento disponibile sul web simula la traduzione di sequenze di mRNA in sequenze di aminoacidi rappresentati secondo il codice ad una lettera.
Il tuo compito
Procedere come descritto sotto:
- Aprite la tabulazione “Sequence 1” e copiate per intero la sequenza di mRNA che inizia con >Sequence1 (comando Ctrl.+C).
- Incollate la sequenza nucleotidica nel box di ricerca EMBOSS Transeq (comando Ctrl. + V).
- Seguite le istruzioni nella tabulazione “EMBOSS Transeq” per tradurre la sequenza.
- Osservate la proteina e cercate di rispondere alle domande nella tabulazione “Questions”.
- Ripetere il procedimento per le 4 sequenze.
EMBOSS Transeq
- Aprite la tabulazione “Sequence 1” e copiate per intero la sequenza di mRNA che inizia con >Sequence1 (scomando Ctrl.+C).
- Incollate la sequenza nucleotidica nel box di ricerca EMBOSS Trranseq (comando Ctrl. + V).
- Lasciate tutte le impostazioni così come sono.
- Cliccate sul pulsante “Submit” e la vostra sequenza verrà tradotta.
- Il risultato sarà disponibile entro pochi secondi.
- Osservate la proteina e cercate di rispondere alle domande nella tabulazione “Questions”.
- Ripetere il procedimento per le 4 sequenze.
Sequenze 1-4
Sequenza 1
>Sequence1_AVGFP
ATGAGTAAAGGAGAAGAACTTTTCACTGGAGTGGTCCCAGTTCTTGTTGAATTAGATGGCGATGTTAATGGGCAAAAATTCTCTGTCAGTGGAGAGGGTGAAGGTGATGCAACATACGGAAAACTTACCCTTAATTTTATTTGCACTACTGGGAAGCTACCTGTTCCATGGCCAACACTTGTCACTACTTTCTCTTATGGTGTTCAATGCTTCTCAAGATACCCAGATCATATGAAACAGCATGACTTTTTCAAGAGTGCCATGCCCGAAGGTTATGTACAGGAAAGAACTATATTTTACAAAGATGACGGGAACTACAAGACACGTGCTGAAGTCAAGTTTGAAGGTGATACCCTTGTTAATAGAATCGAGTTAAAAGGTATTGATTTTAAAGAAGATGGAAACATTCTTGGACACAAAATGGAATACAACTATAACTCACATAATGTATACATCATGGGAGACAAACCAAAGAATGGCATCAAAGTTAACTTCAAAATTAGACACAACATTAAAGATGGAAGCGTTCAATTAGCAGACCATTATCAACAAAATACTCCAATTGGCGATGGCCCTGTCCTTTTACCAGACAACCATTACCTGTCCACACAATCTGCCCTTTCCAAAGATCCCAACGAAAAGAGAGATCACATGATCCTTCTTGAGTTTGTAACAGCTGCTAGGATTACACATGGCATGGATGAACTATACAAA
Sequenza 2
>Sequence2_GFPm
ATGTCTAAAGGTGAAGAATTATTCACTGGTGTTGTCCCAATTTTGGTTGAATTAGATGGTGATGTTAATGGTCACAAATTTTCTGTCTCCGGTGAAGGTGAAGGTGATGCTACTTACGGTAAATTGACCTTAAAATTTATTTGTACTACTGGTAAATTGCCAGTTCCATGGCCAACCTTAGTCACTACTTTCGGTTATGGTGTTCAATGTTTTGCTAGATACCCAGATCATATGAAACAACATGACTTTTTCAAGTCTGCCATGCCAGAAGGTTATGTTCAAGAAAGAACTATTTTTTTCAAAGATGACGGTAACTACAAGACCAGAGCTGAAGTCAAGTTTGAAGGTGATACCTTAGTTAATAGAATCGAATTAAAAGGTATTGATTTTAAAGAAGATGGTAACATTTTAGGTCACAAATTGGAATACAACTATAACTCTCACAATGTTTACATCATGGCTGACAAACAAAAGAATGGTATCAAAGTTAACTTCAAAATTAGACACAACATTGAAGATGGTTCTGTTCAATTAGCTGACCATTATCAACAAAATACTCCAATTGGTGATGGTCCAGTCTTGTTACCAGACAACCATTACTTATCCACTCAATCTGCCTTATCCAAAGATCCAAACGAAAAGAGAGACCACATGGTCTTGTTAGAATTTGTTACTGCTGCTGGTATTACCCATGGTATGGATGAATTGTACAAATAACTGCAG
Sequenza 3
>Sequence3_YFP
AATATTTTTATTAATTCATTAGAAAAATGAGAGGAAGGATTATTATGTTTAAAGGTATAGTAGAAGGTATAGGAATCATTGAAAAAATTGATATATATACTGACCTAGATAAGTATGCAATTCGATTTCCTGAAAATATGTTGAATGGAATTAAAAAGGAGTCGTCAATAATGTTTAACGGATGCTTCTTAACGGTAACTAGCGTGAATTCAAACATTGTCTGGTTTGATATATTTGAAAAAGAAGCACGTAAGCTTGATACTTTTCGGGAATATAAGGTAGGTGACCGAGTAAATTTAGGAACATTCCCAAAATTTGGCGCTGCATCTGGTGGGCATATATTATCAGCAAGGATTTCATGTGTAGCAAGTATTATTGAAATAATAGAAAATGAGGATTATCAACAAATGTGGATTCAAATTCCTGAAAATTTTACAGAGTTTCTTATTGATAAAGACTATATTGCTGTGGATGGTATTAGCTTAACTATTGACACTATAAAAAACAACCAATTTTTCATTAGTTTACCCTTAAAAATAGCACAAAATACAAATATGAAATGGCGAAAAAAAGGTGATAAGGTAAATGTTGAGTTATCAAACAAAATTAATGCTAACCAGTGTTGGTAATTTACTGAGGATAGTAAAAATGAACTGTTTAAAATAATATTTAAATTTTTATTTATAATACAGAGTCAGTTGTTGTAAATAGTCTGAGTGGTAAATAAGTTCTACCATTAATTAAATATTATCCATATTAAATAAAGGATCT
Sequenza 4
>Sequence4_RFP
AGTTTCAGCCAGTGACAGGGTGAGCTGCCAGGTATTCTAACAAGATGAGTTGTTCCAAGAATGTGATCAAGGAGTTCATGAGGTTCAAGGTTCGTATGGAAGGAACGGTCAATGGGCACGAGTTTGAAATAAAAGGCGAAGGTGAAGGGAGGCCTTACGAAGGTCACTGTTCCGTAAAGCTTATGGTAACCAAGGGTGGACCTTTGCCATTTGCTTTTGATATTTTGTCACCACAATTTCAGTATGGAAGCAAGGTATATGTCAAACACCCTGCCGACATACCAGACTATAAAAAGCTGTCATTTCCTGAGGGATTTAAATGGGAAAGGGTCATGAACTTTGAAGACGGTGGCGTGGTTACTGTATCCCAAGATTCCAGTTTGAAAGACGGCTGTTTCATCTACGAGGTCAAGTTCATTGGGGTGAACTTTCCTTCTGATGGACCTGTTATGCAGAGGAGGACACGGGGCTGGGAAGCCAGCTCTGAGCGTTTGTATCCTCGTGATGGGGTGCTGAAAGGAGACATCCATATGGCTCTGAGGCTGGAAGGAGGCGGCCATTACCTCGTTGAATTCAAAAGTATTTACATGGTAAAGAAGCCTTCAGTGCAGTTGCCAGGCTACTATTATGTTGACTCCAAACTGGATATGACGAGCCACAACGAAGATTACACAGTCGTTGAGCAGTATGAAAAAACCCAGGGACGCCACCATCCGTTCATTAAGCCTCTGCAGTGAACTCGGCTCAGTCATGGATTAGCGGTAATGGCCACAAAAGGCACGATGATCGTTTTTTAGGAATGCAGCCAAAAATTGAAGGTTATGACAGTAGAAATACAAGCAACAGGCTTTGCTTATTAAACATGTAATTGAAAAC
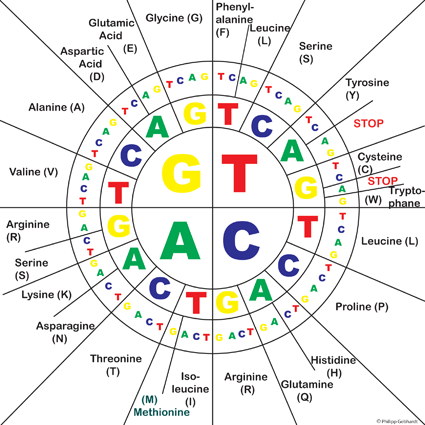
Codon sun
Domande
- Come si traduce una sequenza di DNA in una sequenza di aminoacidi? Descrivete i passaggi. Se volete, usate il codice genetico della tabulazione “Codon sun”.
- Come si può trovare l’open reading frame “giusto”?
- Nel risultato di EMBOSS Transeq , cosa pensate significhi il simbolo * (asterisco)?
Liste attivita
Share: